I haven’t been blogging as much recently, but it hasn’t been
due to laziness (I promise!). In my spare time, I’ve been working on a few
things. Primarily my time is devoted to my side hustles. My goal isn’t to win
the lottery, but to have money working for me when I’m not working. This has
been such a struggle and is very time consuming, but very worth it. I haven’t
stopped learning how to program, though! In fact, my remaining time has been
dedicated to my continuing learning. My time has been dedicated to learning
Node, Angular, Gosu, and Elixir.
When you’re learning a new language, the journey tends to be easier as the concepts translate well. My skillset up until a few months ago only involved object oriented languages, but I recently decided to add Elixir to the mix and delved into the world of functional-programming.
When you’re learning a new language, the journey tends to be easier as the concepts translate well. My skillset up until a few months ago only involved object oriented languages, but I recently decided to add Elixir to the mix and delved into the world of functional-programming.
The question is what does it mean to be object-oriented or
functional-oriented? First, it is important to ask: what is computing? I
believe computing can be summed up as data transformation and transportation.
Every encounter with code I’ve had, including machine learning algorithms,
boils down to taking some input and turning it into output. Perhaps you need to
get data from a database and render in a field on your webpage. That is data
transportation. Or perhaps you’ve made a time clock and need to automatically
compute an employee’s wages for the day. This is data transformation.
We are instructing our computers to transport
and transform data all day. So how are we transforming and transporting our
data? With object-oriented programming this process involves objects, which Zed
Shaw likens to nouns. Our objects are abstractions of our data and, like nouns,
they have properties (adjectives) and they have methods (verbs). We’ve taken
our data and turned it into a digital noun and many applications and
architecture now revolve around this concept. To be sure, this concept has served us well for years, but what if our architecture revolved around data and what we can do with data? This is where functional programming comes into play. Languages like Elixir look like any other language on the surface. Elixir organizes data into modules which essentially says: I have this data and here are some things I can do to that data. This can best be described with code. Data is left alone and things that can be done to that data are separated into their own module.
To better understand this, code is needed. This is a simple Ruby script representing a bank account.

We turn our bank account in a noun. It has properties: an account holder and a balance. It has actions. We can add to the account, we can subtract from the account, and we describe our account to whomever. How might we do this in functional programming? I’ll use Elixir here!

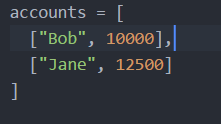
Functional programming offers the advantage of using less lines of code. Our code is also kept separate from our data. Our data looks like this:
Admittedly, now that I’m used to object-oriented, I feel that it is more intuitive, but were I new programmer, I’d think functional oriented makes more sense. The big question right now: which is better? I don’t know the answer to that, but I have had far more luck out using frameworks like Phoenix than I have with Rails or Sails.js. I believe both paradigms are here to stay and offer distinct advantages. This leads me to a new development in my programming journey: the realization that certain tools are good for certain things and that it is good to be a polyglot.
One note before I end this post: you don't need a functional language in order to do functional programming! You can do functional programming in almost every object-oriented language. In fact, Java 8 supports functional programming. You can learn about that here! I hope to be blogging about Elixir and Phoenix in the future. I believe that these technologies will be in serious use in the future!