Recap:
In my last post, I explained how given a set of data we can then create a line that tries to predict outputs. This prediction can be presented as a function, F(x) = y = ax + b. We also discussed how this line could be inaccurate without some analysis of errors.
A Couple Notes:
If anyone is taking Professor Ng’s Coursera course, there may be confusion with to the notation I used and the notation he uses. It is more proper, for the field of machine learning, to use Professor Ng’s notation, but I decided to start with the y = ax + b as it is a more common point and less confusing when starting out.
Also, the notation we use for our data points will come in handy as we progress. Let’s look at our data points and get an understanding of our notation:
X Notation
|
X Value-Living Area
|
Y Notation
|
Y Value-Price
|
x1
|
2104
|
y1
|
400
|
x2
|
1600
|
y2
|
330
|
x3
|
2400
|
y3
|
369
|
x4
|
1416
|
y4
|
232
|
x5
|
3000
|
y5
|
540
|
Also keep in mind, the term for “any given x” or “any given y” would be: x(i) and y(i) respectively.
What is an error?
An error is rather intuitive. Given a predictive function, F(x), measure how far off the predicted outputs are from known outputs. Simply predicted - actual. Imagine if I took F(2104) and determined that y = 500. My error in this case would be 100 (500 - 400). If I took F(1600) and determined that y = 300, then my error would be -30. You may ask, how does one get a negative amount of error? Would you be saying you’re so wrong that you’re right? This is because at this point we are measuring a range rather than error. We handle this squaring our errors. In case you’re curious why we don’t use absolute value, read about Jensen's Inequality.
This can be represented as:

Mean Squared Error and the Cost Function
We can take our function and check the error with each x and y value, but what do we do after that? The error data is not really meaningful to us yet as it is simply a collection of error values. What we’re going to do is very similar to taking the average of collected errors. The sum of all our errors can be represented as:

Where the preceding term, sigma, is just a fancy way of representing a sum. Remember that our m value is the sum of all of our data in the set. For the purpose of our goal, instead of dividing the above term by m, we will multiply it by 2 and put it over one making (f(xi) -yi)2our numerator. Our end equation looks like this and we set our error to a variable J:

In machine learning, J is called the cost function. The one I have provided is different in notation, but fundamentally the same as one you might find in a machine learning textbook. Now you might notice a problem: our original equation is y = ax + b. What do we do with the a and b in this case? We will calculate for mean squared error based off different parameters, which makes our job extremely easy. Think about it this way: we always know what our x and y value will be if a and b are constant, but we need the values of a and b to make our algorithm work. Our calculation of any given a or b is noted as follows:

A Change in Notation
It is at this point, I’d to change the notation in order to align more closely with Professor Ng’s class. We will recognize our b term is a parameter like a and notate each parameter as a. So,
This will help us with the calculus that will happen later on. Similarly, the cost function will look like this:

Finding the right parameters
Our goal now is find values of a that produce the lowest cost, J. By obtaining the minimal value of J, we will then have the most accurate function possible. How do we find the lowest value of J? To do so, we need to find the relationship of a to the cost function. More specifically, we need to see how J changes and at what rate it changes with regards to our parameters. The rate of change in calculus is found by with the derivative. To understand a little better let’s say we had the function:

The way find the derivative is by eliminating the constant, 3, and multiplying the coefficient 2 by the exponent. With this we get 6x and we know that the above function changes at a rate of 6x. So the derivative of the above function (to read as “f prime of x”) is:

However, the cost function takes two parameters and as such we must evaluate the rate of change one variable has on another variable. We do this with a partial derivative. For example, take the following function:
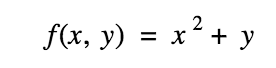
We can then take the derivatives of each variable, x and y, and the find out how they change in relation to one another. The partial derivative is denoted as such:

Essentially what we’re doing is seeing how y changes with regards to x by holding y constant. In the above example, the derivative of y evaluate to 1 and x squared remains constant. So y changes at a rate of x2 with regards to y.
For our cost function, we want to see how a parameter a changes with given set outputs and inputs. Our inputs and outputs are constants when evaluating our functions. The derivative term with respect to our cost function, looks like this:

We could then multiply the derivative term by some value, which we will call , and subtract the product of and the derivative term from our original proposed parameter a. So the algorithm to find the minimum would look like this:
We would then assign the result of this function to the parameters and plug them back into the equation and repeat the process until we converge to the minimum value of our function. This process is called Gradient Descent.
Gradient Descent Visualized
While it might be difficult to understand that algorithm, it is easy to visualize and understand what gradient descent is trying to accomplish. Imagine if we took our x and y terms and expanded a plot to a third dimension. We would represent our cost function value on the z axis and plot the various values of a. A plot might look like this:

You can imagine the function as someone navigating a landscape, where they are standing on a high point and seeking the lowest point in the valley. Each do above represents a step towards the lowest point in the valley, or the minimum. This step is our term and it represents our learning rate. The value we set the learning rate determines the size of the step we take towards the minimum. As such, it is important to select the right learning rate. If the learning rate is too large, then the a value will remain too large and then never reach the minimum. If is too small, then we may never reach the minimum on a practical timescale.
Conclusion
We have taken a function that we believe can predict the price of house given the size of the house. We tested the predictive power of the function by placing the size of the house and seeing how the predicted value differed from each actual value we knew. We then added those errors up and used the value of our parameters in relation to the mean error squared to see what the optimal (or minimal) should be.
If you really think about it, through this long process we were able to learn how to predict the price of a house. Were we to place this process into code and run it, we would see that our code would take in past data and perform a predicting task. It would then learn to improve the predicting task with time. This is the very definition of a learning machine!
In the next post, I will be using Python to make a machine learn.


